NVIDIA Networking
Since April 2020 and the acquisition of Mellanox Technologies, NVIDIA has continued Mellanox network products under the name NVIDIA Networking. These include the Ethernet and InfiniBand solutions. All suitable switches, adapters and accessories can be found on the corresponding sub-pages:
NVIDIA Networking Ethernet NVIDIA Networking InfiniBand NVIDIA Networking CumulusGPU based High Performance Computing
Turbo growth with GPU computing
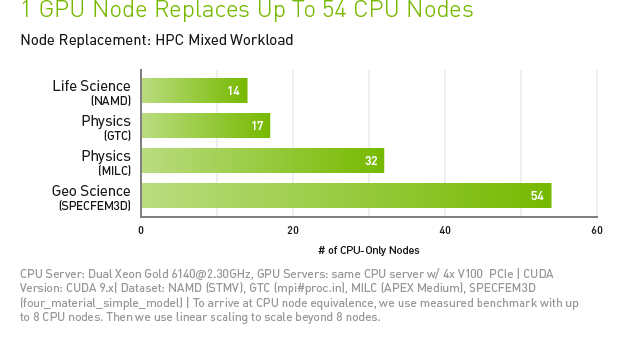
Moore's Law has long been superseded by the law of turbo growth with GPU Computing. Thanks to a highly specialized, parallel graphics processor, special algorithms and optimized application software, dozens of standard CPU servers can be replaced by a GPU-accelerated server. The result is significantly higher application throughput and significant cost savings.
Especially the excellent accessibility and energy efficiency of GPU computing makes it so interesting for HPC and data centers in the future. The fastest supercomputers in the US and Europe, as well as some planned and extremely advanced systems, are already benefiting from the power of the ENVIDIA solution. An example would be the most powerful "Summit" supercomputer at the Oak Ridge National Laboratory, with over 200 PetaFLOPS for HPC and 3 ExaOPS for AI. Summit combines HPC and AI computing with 27,000 NVIDIA Volta GPUs with Tensor processing units. Today, HPC and AI NVIDIA GPUs are at the center of some of the most promising research areas in which HPC is deployed, providing tremendous potential for scientific advances and accelerating innovation in this area.
The Artificial Intelligence (AI), as an integral part, makes it possible to tackle inextricably valid problem by creating models of real conditions based on data from experiments and simulations. In addition, the results can already be displayed in real time, whereas comparable simulations used to take days or months.
NVIDIA Tesla V100-GPU with Tensor processing units
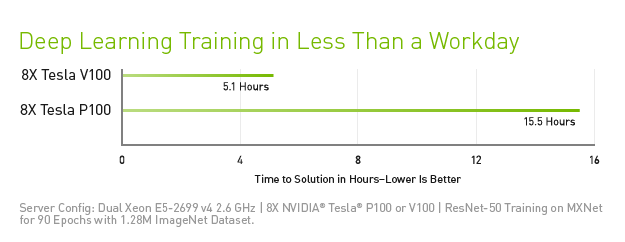
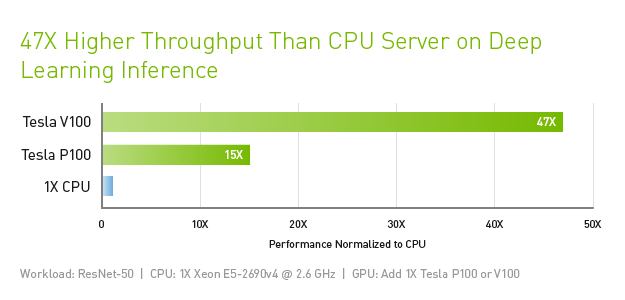
The NVIDIA® Tesla® V100 is considered one of the most advanced data center graphics processors, thanks to the power of its Volta architecture. Designed for the convergence of HPC and AI, it is well-suited as a platform for HPC systems used for scientific simulations and for identifying valuable information in data. A single server running Tesla V100 GPUs can replace hundreds of standard pure CPU servers on both traditional HPC and AI workloads. As a result, the resulting performance can be made available to data scientists, researchers, and engineers to accomplish challenges previously considered insurmountable.
The GPU is available in two variants, the PCle model is designed for optimal versatility in all workloads on HPC, while the NVLink variant provides high performance in deep learning. Both cards are available with 16GB or 32GB HBM2 memory.
 Nvidia Tesla V100 GPU for PCle or NVLink (16 or 32GB)
Nvidia Tesla V100 GPU for PCle or NVLink (16 or 32GB)Technical data & specifications - Tesla V100
- PERFORMANCE with NVIDIA GPU Boost™
| Model: | Tesla V100 for NVLink | Tesla V100 for PCIe |
| Double accuracy: | 7.8 TeraFLOPS | 7.0 TeraFLOPS |
| Simple accuracy: | 15.7 TeraFLOPS | 14.0 TeraFLOPS |
| Deep Learning: | 125 TeraFLOPS | 112 TeraFLOPS |
| NVIDIA Tensor cores: | 640 | 640 |
| NVIDIA CUDA™ cores: | 5.120 | 5.120 |
| Interconnect bandwidth: Bi-Directional | 300 GB/s | 32 GB/s |
| Memory: CoWoS-HBM2 | 32/16 GB | 32/16 GB |
| Bandwidth: | 900 GB/s | 900 GB/s |
| System Interface: | PCIe Gen3 | NVIDIA NVLink |
| Form Factor: | PCIe FullHeight/Length | SXM2k |
| Max. Power: | 300 Watt | 250 Watt |
| ECC: | ✔ | ✔ |
| Cooling: | Passiv | Passiv |
| Compute APIs: | CUDA, DirectCompute, OpenCL, OpenACC | |